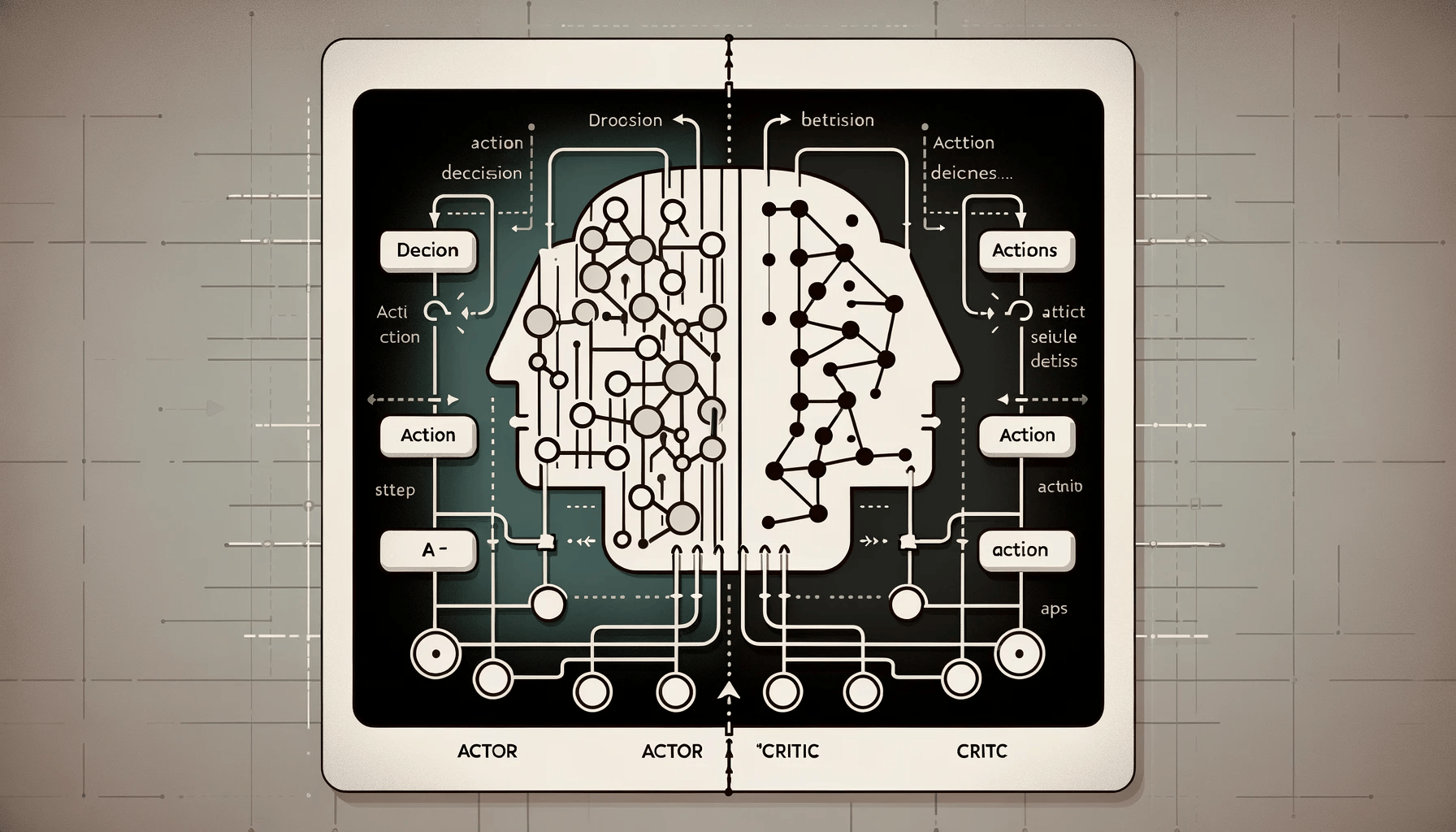


1 算法介绍:演员-评论家(Actor-Critic)模型
演员-评论家(Actor-Critic)模型是一种结合了基于值的方法和基于策略的方法的强化学习框架。这个模型的核心思想是将策略决策(演员)和值函数估计(评论家)的优点结合起来,以期达到更好的学习效率和策略性能。在以下内容中,我们将详细探讨演员-评论家模型的原理、结构、以及它如何克服其他方法的限制。
演员部分负责基于当前策略选择动作。这个策略通常是随机的,允许算法在探索(尝试新动作)和利用(选择已知最佳动作)之间取得平衡。演员的策略是通过某种参数化形式实现的,一般使用神经网络,其参数通过策略梯度方法更新。具体解释如下:
– 输入: 演员网络的输入通常是环境的当前状态。
– 输出: 输出是对每个可能动作的概率分布 (在离散动作空间中) 或者特定动作的参数 (如均值和标准差,在连续动作空间中)。
![图片[1]-演员-评论家模型-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2023/12/20231212123246187-1024x567.png)
演员的学习过程
– 损失函数: 演员网络的训练通常通过策略梯度方法,例如REINFORCE或Actor-Critic方法的策略梯度。损失函数通常是负的对数概率乘以优势函数 (advantage function),即 \(-\log (\pi(a \mid s)) \times A(s, a)\) ,其中 \(\pi(a \mid s)\) 是在状态 \(s\) 下选择动作 \(a\) 的概率,而 \(A(s, a)\) 是动作的优势值。
– 优化方法: 梯度上升是常用的优化方法,用于最大化奖励期望。
评论家部分估计所选动作的值,通常是状态-动作对的Q值或仅是状态的价值V。这个评价帮助演员判断所选择的动作是好是坏。评论家的更新通常依赖于TD-Learning或其他值函数近似方法,并且它提供的价值反馈用于指导演员的策略更新。具体解释如下:
– 输入: 输入通常是当前状态或状态和动作的组合。
– 输出: 输出是对当前状态或状态-动作对的价值估计,即 \(Q\) 值 (状态-动作值函数) 或 \(V\) 值 (状态值函数)。
评论家的学习过程
– 损失函数: 评论家的损失函数通常是TD误差的平方,即 \(\left[R+\gamma V\left(s^{\prime}\right)-V(s)\right]^2\) ,其中 \(R\)是奖励, \(\gamma\) 是折扣因子, \(V(s)\) 和 \(V\left(s^{\prime}\right)\) 分别是当前状态和下一个状态的价值估计。
– 优化方法: 梯度下降是最常用的优化方法,用于最小化价值估计的误差。
2 演员-评论家模型算法训练
在演员-评论家(Actor-Critic)模型中,学习过程涉及到一个交互式的环节,其中演员负责选择动作,而评论家则评估这些动作的好坏。下面详细解释这个过程的每个步骤:
![图片[2]-演员-评论家模型-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2023/12/20231212123744473.png)
Step1:基于当前策略,演员选择一个动作
演员部分的神经网络根据当前环境状态输入,输出一个动作。这个动作可以是具体的行动(在离散动作空间中),或者是动作的参数(如在连续动作空间中的动作均值和标准差)。演员的策略通常包含一定的随机性,以便于探索(探索新动作)和利用(选择已知的最佳动作)之间取得平衡。
Step2:环境反馈
环境根据选择的动作返回新的状态和奖励:一旦演员执行了一个动作,环境便会做出反应,返回新的状态和与该动作相对应的奖励。这些信息对于后续的学习更新至关重要。
Step3:学习更新
评论家使用TD误差来评估所采取动作的价值。评论家会计算TD误差,即实际获得的回报(包括即时奖励和对未来状态的价值估计)与之前预测的价值之间的差异。这个TD误差反映了评论家对演员行为的评价,一个正的TD误差表示实际结果比预期的好,而一个负的TD误差则意味着实际结果比预期的差。 同时,演员根据评论家的反馈来更新其策略,利用评论家提供的TD误差,演员更新其策略以增加在类似情境下选择更有价值动作的概率。这种策略更新通常通过梯度上升方法实现,即调整演员神经网络的参数,使得那些获得高评价(即高TD误差)的动作在未来被更频繁地选中。
Step4:迭代下去直到轨迹结束
演员-评论家模型通过这样的循环来不断学习和适应,演员基于当前策略做出选择,环境提供反馈,评论家评估选择的结果,然后演员根据这些评估来优化其决策过程。
3 演员-评论家模型算法的优缺点
演员-评论家(Actor-Critic)模型是一种结合了策略梯度和值函数近似的强化学习方法,因此也理所当然的继承了他们具有各自的优点和局限性。
优点如下:
1.稳定性与效率的结合:
演员-评论家模型结合了基于策略的方法(如REINFORCE)的优点和基于值的方法(如Q学习或DQN)的优点,比单独使用策略梯度方法或值函数方法更稳定和高效。
2.适用于连续动作空间:
与仅基于值的方法(如DQN)不同,演员-评论家模型适用于连续动作空间的问题,使其在处理诸如机器人控制等问题时更为有效。这个优点是继承自基于策略的强化学习的。
3.减少方差,提高学习效率:
评论家的引入帮助减少策略估计的方差,从而提高学习的效率。这个优点是继承自基于价值的强化学习的。
4. 在线学习和离线学习:
可以应用于在线学习(从每个步骤中学习)和离线学习(从一个完整的情节中学习),提供灵活的学习方式。
缺点如下:
1. 复杂性和计算成本:
需要同时训练两个模型(演员和评论家),这可能导致模型更加复杂和计算成本更高。
2. 稳定性问题:
尽管比纯策略梯度方法更稳定,但是演员-评论家算法的稳定性仍然不如传统的基于值的方法,如DQN。
3. 调参难度:
需要调整更多的超参数(如两个不同网络的学习率、折扣因子等),调参可能比单一模型方法更加困难。
4. 过度估计的风险:
由于评论家模型可能过度估计值函数,特别是在使用函数逼近器(如神经网络)时,可能导致学习过程不稳定。
结论
演员-评论家模型在处理复杂的强化学习问题时提供了一个平衡效率和稳定性的有力工具,特别是在连续动作空间和需要策略与值函数同时学习的情景中。然而,其增加的复杂性、调参难度和潜在的稳定性问题也需要特别注意。在实际应用中,如何根据特定问题的需求来平衡这些优点和缺点,是设计和实施演员-评论家模型的关键挑战。
4 对比生成对抗网络和演员-评论家模型算法
先简短回顾一下这两个模型。
生成对抗网络(GANs)
基本概念:GANs 由两部分组成,生成器(Generator)和判别器(Discriminator)。生成器的目标是创建逼真的数据(如图片),而判别器的目标是区分真实数据和生成器产生的假数据。
训练性质:在GANs中,生成器和判别器呈对抗关系。生成器尝试欺骗判别器,而判别器努力不被欺骗。这种对抗过程促进了两者的能力提升,最终生成器能产生极为逼真的数据。
学习机制:GANs 的学习过程是一个动态平衡的游戏,其中生成器不断改进其生成的数据以逃避判别器的识别,而判别器则不断提升其辨别能力。
演员-评论家模型
基本概念:演员-评论家模型由两部分组成,演员(Actor)和评论家(Critic)。演员负责选择动作,而评论家评价这些动作并提供反馈。
训练性质:与GANs不同,演员-评论家模型中的演员和评论家是合作关系。评论家提供的反馈帮助演员改进其策略,以此优化动作选择过程。
学习机制:在演员-评论家模型中,演员的动作选择受到评论家提供的价值评估指导,评论家基于演员的表现来调整自己的价值估计。这种机制有助于同时优化策略选择和价值判断。
注意思考一个问题:评论家提供的反馈帮助演员改进其策略,以此优化动作选择过程。可是在GAN中,也是判别器给生成器反馈以提升生成质量,为什么训练性质一个是对抗,一个是合作?
这是因为两种模型的核心区别在于它们的目标和动态互动方式的不同。
从目标中分析,GANs的生成器和判别器有完全相反的目标。生成器的目标是产生足以欺骗判别器的假数据,而判别器的目标是准确区分真实数据和生成器产生的假数据。它们之间的互动是一个零和游戏(zero-sum game),即一方的胜利意味着另一方的损失。
而演员和评论家的目标是相互补充的。演员需要选择最佳动作,而评论家则提供关于这些动作好坏的反馈,以帮助演员做出更好的决策。他们共同工作,以提高整体的决策质量,实现共同的目标(如最大化累积回报)。
从互动方式上来解释,GANs:互动是基于对立和欺骗的。生成器试图通过生成尽可能逼真的数据来“欺骗”判别器,而判别器则要识破这些欺骗。
而演员-评论家的互动是基于指导和改进的。评论家通过评估演员的行为来提供指导性反馈,而演员则利用这些反馈来优化自己的行为策略。
这种区分对于理解这两个模型在设计、优化和应用上的不同非常重要。对抗性和合作性不仅决定了这两种模型的内部动态,也影响着模型的训练方式和稳定性。例如,在GANs中,平衡生成器和判别器的能力是实现高质量生成结果的关键,而在演员-评论家模型中,有效地整合演员和评论家的反馈来稳步提高性能则更为重要。
简而言之,尽管两种模型都涉及一种“反馈”机制,但它们的互动方式、目标和最终的应用背景决定了一个是基于对抗的,另一个是基于合作的。
到底是对抗提升好一些,还是合作共赢好一些?实际上,选择对抗还是合作,取决于具体的应用场景、目标和所面临的问题的性质。每种方法都有其独特的优势和局限性。
GAN的魅力在于创新性和创造性,在生成新内容(如图像、音乐、文本)方面,对抗方法能够产生新颖、多样且逼真的结果。这是因为通过对抗训练可以揭露和改进模型的弱点,实现相互进化。局限性则是对抗训练可能导致模型训练不稳定,难以收敛。而且由于模型的对抗本质,最终结果可能具有不可预测性。
演员-评论家模型的魅力在于协同工作,合作模型能够在多个组件间建立协同,推动共同目标的实现,例如在强化学习任务中提升决策质量,获得最大回报。相比于对抗模型,合作模型通常训练更加稳定和高效。局限性则体现在创造力有限,合作模型可能不如对抗模型那样在创造力和创新性上表现突出。
综合考虑,如果目标是探索新的、未知的或创造性的内容生成,对抗方法可能更适合。 如果目标是稳定地解决特定问题或在预定义的框架内优化性能,合作模型可能更优。这就是为什么GAN模型一般负责生成任务,而演员-评论家则是强化学习领域模型的原因。
进一步的可以将对抗与合作的思考上升到哲学层面,特别是在人际关系和社会交往上,我们可以探讨如何在竞争与合作之间寻找平衡,以及这两种态度如何影响个人和社会的发展。
在哲学的视角下,人性的本质及其在社会发展中的作用常被解读为对抗与合作两种基本态度的体现。托马斯·霍布斯认为人的自然状态是“人对人是狼”,这一观点强调了个体间的竞争、自利和生存斗争。而让-雅克·卢梭则提出相反的看法,他认为人本性善良,强调社会和合作是人类文明发展的基石。
对抗在社会发展中通常被视为创新和进步的催化剂。竞争和挑战能激发个人潜能,推动技术、艺术乃至社会制度的发展。然而,合作则有助于社会的稳定性和和谐。通过共享资源、知识和技能,个体和集体能够共同应对复杂挑战,建立更强大的社会联系。
在道德和伦理的层面,对抗可能涉及到竞争中的公正性、诚实和责任等复杂问题,而合作则更多地强调共情、利他主义和集体福祉的重要性。
人际关系中的对抗和合作也是必不可少的两个方面。对抗有助于个体建立自我边界和独立性,而合作则增强了关系的亲密度和团队的凝聚力。对抗,特别是正面的对抗如公平竞争和开放辩论,能够激发新思想和个人成长。而合作,则通过相互支持和理解,在共同面对挑战时加深了彼此之间的信任和理解。
最终,我们看到,在哲学和人际关系层面,对抗与合作不是简单的二分法,而是相互依赖、互补的两种力量。找到对抗和合作之间的平衡,是个体和社会不断探索和调整的过程。这不仅是对人性、道德伦理和社会发展的深刻理解,也是我们认识自身和周围世界的方式。
这或许就是算法的魅力吧。











暂无评论内容