


论文链接:https://arxiv.org/pdf/1904.09664v2
代码链接:https://github.com/facebookresearch/votenet;https://github.com/open-mmlab/mmdetection3d
摘要
VoteNet 是2019年提出的基于点云的3D目标检测算法,旨在解决传统方法依赖2D检测器或体素化导致几何信息丢失的问题。其核心创新在于将霍夫投票(Hough Voting)机制与深度学习结合,通过端到端优化的方式直接处理原始点云数据,无需依赖RGB信息或体素化操作。VoteNet利用PointNet++提取点云特征,生成指向物体中心的虚拟投票点,并通过聚类和聚合生成高质量的3D候选框。实验表明,VoteNet在ScanNet和SUN RGB-D两个数据集上超越现有方法,仅使用几何信息的 VoteNet 明显优于使用 RGB 和几何甚至多视图 RGB 图像的现有技术。
主要贡献
- 深度霍夫投票的端到端框架:将传统霍夫投票改进为可微分架构,通过神经网络自动学习投票偏移量,解决了传统方法依赖手工特征和离线代码本的问题。投票机制使稀疏点云中的前景点向目标中心偏移,形成聚类,增强上下文聚合能力。
- 纯几何信息的3D检测性能突破:介绍了一个以点云为中心的三维检测框架,该框架直接处理原始数据,无论是在体系结构还是在对象方案中都不依赖于任何二维检测器。在仅使用点云几何信息的条件下,VoteNet在ScanNet和SUN RGB-D数据集上达到SOTA性能,验证了投票机制对远距离目标中心预测的有效性。
- 基于点的局部特征提取网络:借鉴了PointNet++,通过采用一种分层深层网络来直接处理点云数据。这种方法减少了将点云转化为常规结构的需求,有效避免了在量化过程中可能出现的信息丢失。
网络结构

-
点云特征提取(Backbone)
-
使用PointNet++作为主干网络,通过多级Set Abstraction层对点云进行采样和局部特征提取,生成种子点(Seed Points)及其特征。每个种子点包含坐标和语义特征信息。
-
-
投票模块(Voting Module)
-
每个种子点通过全连接网络预测偏移量(指向目标中心的XYZ位移)和特征偏移,生成虚拟投票点。背景点的偏移量通常较小或无意义,而前景点偏移量集中于目标中心,形成聚类。
-
-
投票聚类(Clustering)
-
采用最远点采样(FPS)选取初始聚类中心,再通过半径搜索聚合邻近投票点。聚类结果通过PointNet提取全局特征,生成候选框参数(位置、尺寸、方向)。
-
-
候选框优化(Proposal Module)
-
对每个聚类进行特征聚合,输出物体置信度、边界框回归参数(7自由度)和语义分类得分。损失函数包含投票偏移回归(Smooth L1 Loss)、物体置信度分类(Focal Loss)和语义分类(交叉熵损失)
-
实验结果

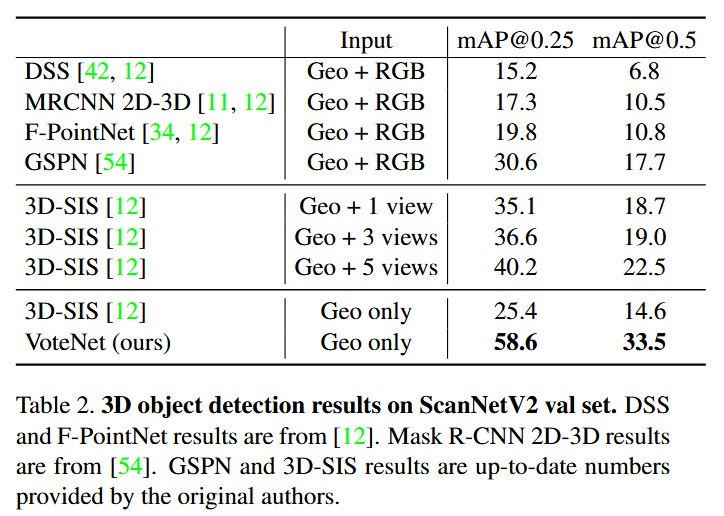
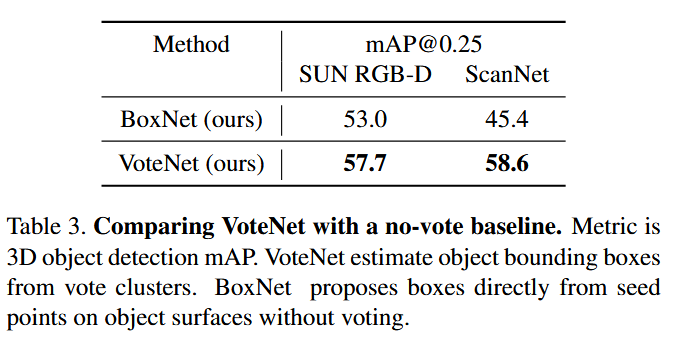
总结
-
高效稀疏计算:直接处理原始点云,避免体素化或投影导致的信息损失。
-
鲁棒的上下文聚合:投票机制显著改善远距离目标(如桌子、浴缸)的检测效果。
-
多场景适应性:在复杂室内场景(如杂乱房间)中仍能准确区分相邻物体(如沙发与椅子)。


没有回复内容