

0.引言
作为CVPR2017年的最佳论文,DenseNet模型脱离了通过加深网络层数(如VGGNet、ResNet)和加宽网络结构(如GoogLeNet)来提升网络性能的定式思维。转而从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了梯度弥散问题的产生。结合信息流和特征复用的假设,DenseNet当之无愧成为2017年计算机视觉顶会的年度最佳论文。
先列下DenseNet的几个优点,感受下它的强大:
(1)减轻了梯度消失问题。
(2)加强了特征的传递,更有效地利用了不同层的特征。
(3)网络更易于训练,并具有一定的正则效果。
(4)因为整个网络并不深,所以一定程度上较少了参数数量。
DenseNet论文名称:Densely Connected Convolutional Networks
论文下载:https://arxiv.org/pdf/1608.06993.pdf
1.模型设计动机
卷积神经网络在沉睡了近20年后,如今成为了深度学习方向最主要的网络结构之一。从一开始的只有5层结构的LeNet,到后来拥有19层结构的VGGNet,再到首次跨越100层网络的Highway Networks与1000层的ResNet,网络层数的加深成为CNN发展的主要方向之一;另一个方向则是以GoogLeNet为代表的加深网络宽度。
随着CNN网络层数的不断增加,梯度消失和模型退化的问题出现在了人们面前,BN的广泛使用在一定程度上缓解了梯度消失的问题,而ResNet和Highway Networks通过构造旁路,进一步减少梯度消失和模型退化的产生。Fractal Nets模型通过将不同深度的网络并行化,在获得了深度的同时保证了梯度的传播,Stochastic Deep Network模型通过对网络中一些层进行失活,既证明了ResNet深度的冗余性,又缓解了上述问题。尽管这些网络框架实现方法不同,但它们都包含了相同的核心思想,即跨网络层连接不同层的特征图。
何恺明在提出ResNet的时候做了这样一个假设:如果一个深层网络增加了几个能够学习恒等映射的层,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络。换句话说,如果将能够学习恒等映射的层添加到某个网络中以形成一个新的网络,那么最坏的结果也只是新网络中的这些层在训练后变成了恒等映射,而不会影响原始网络的性能。同样的,DenseNet在提出时也做过类似假设:与其多次学习冗余的特征,特征复用是一种更好的特征提取方式。
2.DenseNet模型结构
假设输入为一个图片x0,经过一个L层的神经网络,第l层的特征输出记作xl。
残差连接如公式1所示:
\(x_l=H_{_l}(x_{_{l-1}})+x_{_{l-1}}\)
对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换。
对于DenseNet而言,l层的输出是之前所有层的输出集合,如公式2所示:
\(x_{_l}=H_{_l}([x_{_0},x_{_1},\cdots,x_{_{l-1}}])\)
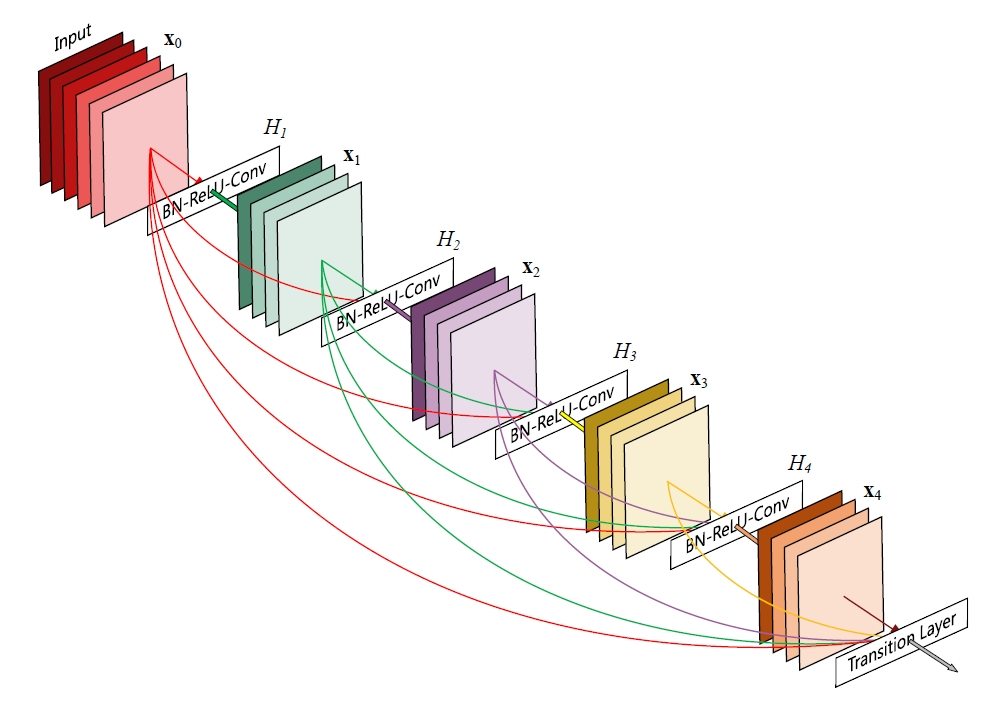
其中[]代表拼接(Concatenation),既将第0层到l-1层的所有输出特征图在通道维度上组合在一起。这里所用到的非线性变换H为BN+ReLU+Conv(3×3)的组合。所以从这两个公式就能看出DenseNet和ResNet在本质上的区别,DenseBlock是DenseNet网络的重要组成部分,从DenseNet网络中节选出来的DenseBlock模块如图1所示。
2.1DenseBlock
![图片[1]-DenseNet:特征复用真香-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240226224209570.png)
虽然这些残差模块(DenseBlock)中的连线很多,但是它们代表的操作只是一个空间上的拼接,并不是实际上的加减乘除运算,所以DenseNet相比传统的卷积神经网络可训练参数量更少。但是,为了在网络深层实现拼接操作,必须把之前的计算结果保存下来,这就比较占内存了。这是DenseNet的一大缺点。DenseNet模型代码如下:
class _DenseBlock(nn.ModuleDict):
def __init__(self, num_layers, input_c, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(input_c + i * growth_rate, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
2.2下采样层
由于在DenseNet中需要对不同层的特征图进行拼接操作,所以需要不同层的特征图保持相同的尺寸,这就限制了网络中下采样的实现。为了使用下采样,DenseNet被分为了多个阶段,每个阶段包含多个Denseblock,阶段之间进行下采样操作,如图2所示。
![图片[2]-DenseNet:特征复用真香-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240226224606162.png)
在同一个DenseBlock中要求特征图尺寸保持相同大小,在不同DenseBlock之间设置过渡层来实现下采样操作,具体来说,过渡层由BN+Conv (Kernel Size 1×1)+Average-Pooling (Kernel Size 2×2)组成。
注意这里1×1卷积是为了对特征通道数量进行降维;而池化才是为了降低特征图的尺寸。
在DenseNet模型中,DenseBlock的每个子结构都将前面所有子结构的输出结果作为输入。例如,假设我们考虑Dense Block 3,该Block包含32个3×3的卷积操作。如果每一层输出的特征通道数为32,那么第32层的3×3卷积操作的输入通道数将是前31层所有输出的累积,即31×32,加上上一个Dense Block的输出特征通道数。这可以使得特征通道数达到近1000。
为了降低特征通道数,DenseNet在每个DenseBlock后引入了过渡层,其中使用了1×1的卷积核进行降维操作。过渡层包含一个取值范围为0到1的参数Reduction,用于控制输出通道数相对于输入通道数的比例。默认情况下,参数Reduction设为0.5,这意味着过渡层将特征通道数减少到原来的一半,然后将结果传给下一个DenseBlock。
此外,为了防止过拟合,模型在最后的神经网络层中引入了Dropout操作,用于随机丢弃一部分神经元,降低模型复杂度。代码如下:
class _Transition(nn.Sequential):
def __init__(self, input_c: int, output_c: int):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(input_c))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(input_c, output_c, kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
2.3Growth rate
在DenseBlock中,假设每一个卷积操作的输出为K个特征图,那么第i层网络的输入便为(i-1)×K ,加上上一个DenseBlock的输出通道,这个K在论文中被称为Growth Rate,默认为32。这里我们可以看到DenseNet和现有网络的一个主要的不同点:DenseNet可以接受较少的特征图数量32作为网络层的输出。具体网络参数见表1。
![图片[3]-DenseNet:特征复用真香-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240226225150131-1024x464.png)
值得注意的是这里每个DenseBlock的3×3卷积前面都包含了一个1×1的卷积操作,就是瓶颈层(Bottleneck Layer),目的是减少输入的特征图数量,既能对通道数量降维来减少计算量,又能融合各个通道的特征。
3.DenseNet模型比较
DenseNet与ResNet的对比如图3所示,在相同的错误率下,DenseNet的参数更少,计算复杂度也更低。
![图片[4]-DenseNet:特征复用真香-点头深度学习网站](https://venusai-1311496010.cos.ap-beijing.myqcloud.com/wp-content/upload-images/2024/02/20240226225354435-1024x377.png)
但是,DenseNet在实际训练中是非常占用内存的。原因是在计算的过程中需要保留浅层的特征图为了与后面的特征图进行拼接。简单来说,虽然DenseNet参数量少,但是训练过程中的中间产物(特征图)多;这可能就是DenseNet不及ResNet流行的原因吧。











暂无评论内容