









最新发布
排序

机器学习简介
1 机器学习基础 1.1 机器学习的定义与核心概念 为了更深入地理解机器学习,我们可以从以下核心概念入手: 数据驱动:机器学习完全依赖于数据。这些数据既可以是结构化的,如表格,也可以是非结...

测试用博客文件
关于文章的测试 这是一个引言,下面是一个文章链接,和一个文章列表 点击左边的 + 打开代码框 PythonJavaScriptMATLAB dict = {'name': 'zhangsan', 'age': 18} print(dict) let num = 2 consol...

聚类算法之层次聚类 (Hierarchical Clustering)
层次聚类是一种非常独特和强大的聚类方法,与众多其他的聚类技术相比,它不仅为数据集提供了一个划分,还给出了一个层次结构,这在某些应用中是非常有价值的。在生物信息学、社会网络分析、市场...

聚类算法之DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN是在1990年代后期推出的一种聚类方法,它迅速成为基于密度的聚类技术中最受欢迎和广泛使用的算法之一。与传统的聚类方法如K-means不同,DBSCAN的主要优势在于其能够识别出任意形状的聚类...

降维算法之t-SNE (t-Distributed Stochastic Neighbor Embedding)
t-SNE是一种用于探索高维数据结构的非线性降维技术。它特别适用于高维数据的可视化,因为它能够在低维空间中保留原始高维数据的局部结构。由于这个特性,t-SNE在机器学习和数据分析领域越来越受...

降维算法之主成分分析 (Principal Component Analysis, PCA)
主成分分析(PCA)是一种统计方法,用于减少数据的维度,同时尽量保留原始数据中的方差。PCA在机器学习和数据可视化中有着坚实的地位,因为它可以有效地简化数据,同时保留其核心特征。 1 算法...

降维算法之奇异值分解 (Singular Value Decomposition, SVD)
引言 在机器学习和数据分析领域,当数据的维度特别高时,处理和分析数据就会变得尤为困难。这是因为随着维度的增加,数据的稀疏性也会增加,这种现象被称为“维度的诅咒”。为了克服这个挑战,...

假设检验
假设检验的目的与参数估计的目的相同,都是根据样本求总体的参数,但是思想正好相反。可以把参数估计看作正推,即根据样本推测总体:而假设检验是反证,即先在总体上作某项假设,用从总体中随机...
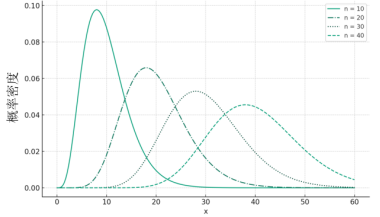
统计量和抽样分布
统计量 在数理统计学中,把研究对象的全体所构成的集合称为总体或母体,而把组成总体的每一个元素称为个体。在实际中,总体的分布往往不可得,因此统计学基本可以看作是用样本来推测总体分布情...
大数定律与中心极限定理
大数定律与中心极限定理是统计学家总结出的自然现象,是概率统计的基石。很多定理和推论都是基于它们之上的研究。 大数法则 讲个故事,一位数学家调查发现,欧洲各地男婴与女婴的出生比例是22:...
经验概率分布
先来具体看一下经验分布函数的定义:首先,根据大数定理(详见1.4.1节),在抽样的次数足够大时,可以把抽样结果的频率当做概率。所以经验分布函数的核心思想就是把频率分布函数当作概率分布函...

