



最新发布第17页
排序

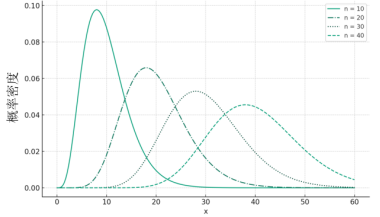
经验概率分布
先来具体看一下经验分布函数的定义:首先,根据大数定理(详见1.4.1节),在抽样的次数足够大时,可以把抽样结果的频率当做概率。所以经验分布函数的核心思想就是把频率分布函数当作概率分布函...
大数定律与中心极限定理
大数定律与中心极限定理是统计学家总结出的自然现象,是概率统计的基石。很多定理和推论都是基于它们之上的研究。 大数法则 讲个故事,一位数学家调查发现,欧洲各地男婴与女婴的出生比例是22:...
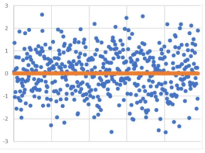
参数估计
统计推断是依据从总体中抽取的一个简单随机样本对总体进行分析和判断。统计推断的基本问题可以分为两大类:一类是参数估计问题,一类是假设检验问题。本节主要讨论总体参数的点估计和区间估计。...
统计量和抽样分布
统计量 在数理统计学中,把研究对象的全体所构成的集合称为总体或母体,而把组成总体的每一个元素称为个体。在实际中,总体的分布往往不可得,因此统计学基本可以看作是用样本来推测总体分布情...
假设检验
假设检验的目的与参数估计的目的相同,都是根据样本求总体的参数,但是思想正好相反。可以把参数估计看作正推,即根据样本推测总体:而假设检验是反证,即先在总体上作某项假设,用从总体中随机...

相关性分析
相关性分析 在函数关系(FunctionalRelationship)中,一个变量完全由另一个变量决定。例如,给定一个方程\(y=2x+3\) ,对于每一个\(x\) 的值, \(y\) 只有一个确定的值。这种关系可以是线性的、...

微分与函数的单调性、极值和凹凸性
函数单调性 函数单调性定义:若\(fx)\)在\((a,b)\)内可导,如果\(f'(x)>0\),那么函数在\((a,b)\)内单调递增;如果\(f'(x)<0\),那么函数在\((a.b)\)内单调递减。 用微分的定义(微分解释了...

偏微分与全微分
在机器学习中,许多函数都是多变量的。需要知道每个输入变量的变化如何影响输出。偏微分正是用于这个目的的。例如,在线性回归中可能要最小化多变量函数(即损失函数)。偏微分指明每个权重的变...
梯度与方向导数
梯度是机器学习中的核心概念,尤其是在优化中,梯度提供了一个方向,指明如何调整参数以最小化损失函数。在梯度下降算法中,使用梯度的负方向来更新模型的权重,以逐步减少误差。 梯度是一个向...

泰勒公式与麦克劳林公式
泰勒公式\(P_n(x)\) 泰勒公式允许用多项式来近似复杂的函数,这在算法中有时用于简化计算。例如,在高斯过程回归和一些其他贝叶斯方法中,泰勒展开用于线性化关于后验的计算。 泰勒公式的本质是...

