
AI新手村 第2页
AI新手村是为初学者量身打造的学习模块,专注于人工智能的基础数学知识、Python编程技巧及环境配置教程。通过深入浅出的教学内容,帮助你快速掌握所需的基础技能,同时提供丰富的测试习题,助力巩固学习成果。
排序

偏微分与全微分
在机器学习中,许多函数都是多变量的。需要知道每个输入变量的变化如何影响输出。偏微分正是用于这个目的的。例如,在线性回归中可能要最小化多变量函数(即损失函数)。偏微分指明每个权重的变...

梯度与方向导数
梯度是机器学习中的核心概念,尤其是在优化中,梯度提供了一个方向,指明如何调整参数以最小化损失函数。在梯度下降算法中,使用梯度的负方向来更新模型的权重,以逐步减少误差。 梯度是一个向...

泰勒公式与麦克劳林公式
泰勒公式\(P_n(x)\) 泰勒公式允许用多项式来近似复杂的函数,这在算法中有时用于简化计算。例如,在高斯过程回归和一些其他贝叶斯方法中,泰勒展开用于线性化关于后验的计算。 泰勒公式的本质是...

重识积分
积分的几何解释是:该函数曲线下的面积。 积分的物理解释是: 积分的物理意义随不同物理量而不同,比如对力在时间上积分就是某段时间内力的冲量;如果是对力在空间上的积分就是某段位移里力做的...
不定积分和反导数
不定积分在机器学习中主要用于计算函数的原函数,尤其是在概率密度函数和累积分布函数之间的转换中。例如,在概率论和统计中,累积分布函数 (CDF) 是概率密度函数 (PDF) 的不定积分。对于某些模...

线性方程组
线性方程组与矩阵 先从线性方程组开始讲起,线性方程组的一般形式如下所示: $$\left\{\begin{aligned}a_{11}x_1+a_{12}x_2+&\cdots +a_{1n}x_n=b_1\\a_{21}x_2+a_{22}x_2+&\cdots +a_{...

重拾微分
微分(differential)和导数(derivative)都与函数的变化率有关,它们是两个相关但不完全相同的概念。首先一起深入了解这两者的定义和区别。 导数 导数描述了一个函数在某一点上的切线斜率。如...
离散型分布
1.两点分布 如果随机变量(X) 的分布列如下: $$\begin{array}{l}P{X=1}=p\bigl(0<p<1\bigr)\\P{X=0}=q=1-p\end{array}$$ 则称(X) 服从两点分布。两点分布也叫伯努利分布(Bermoulli)或0-...

微分的链式法则
在机器学习中,尤其是在深度学习和神经网络中,链式法则用于计算复合函数的导数,这在反向传播算法中尤为关键。具体来说,当训练一个深度神经网络时,需要计算损失函数相对于每个权重的梯度。由...
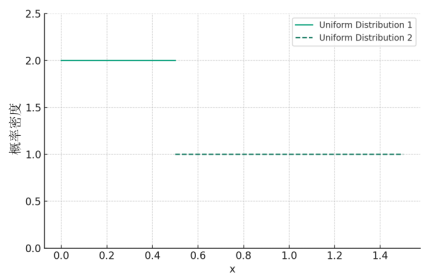
连续型分布
概率密度函数 对于连续型随机变量,由于其取值不能一一列举出来,因而不能用离散型随机变量的分布列来描述其取值的概率分布情况。但人们在大量的社会实践中发现连续型随机变量落在任一区间([a,b...

